Leadership Skills: Managing AI Agents vs. Humans
Leadership quality has a significant impact on firm productivity and can even affect national prosperity, but measuring individual leadership skills is difficult. Existing methods require observing prospective leaders working with multiple randomly assigned groups, an undertaking that can be both logistically complex and expensive.
In Measuring Human Leadership Skills with AI Agents (NBER Working Paper 33662), Ben Weidmann, Yixian Xu, and David J. Deming designed an experiment to test whether the task of managing AI agents could provide a viable alternative to managing human teams. The researchers found that leadership performance with AI agents strongly predicts leadership effectiveness with human teams, which suggests that measuring the former could offer a simpler, more cost-effective method of assessing leadership capabilities than existing approaches.
Managers who are more successful leading teams of AI agents are also more successful with human teams.
The researchers carried out a lab experiment in which human leaders completed a series of collaborative problem-solving tasks with two different types of teams: one composed of AI agents and another composed of humans. Each leader was randomly assigned to six different human teams, which allowed the researchers to isolate each leader’s causal contribution to team performance. This was subsequently compared with performance when leading AI teams.
The experiment used a modified “Hidden Profile” task, where essential information is distributed among team members, requiring effective communication and collaboration to solve problems. Leaders needed to gather information, manage team time, and synthesize collective knowledge into final decisions.
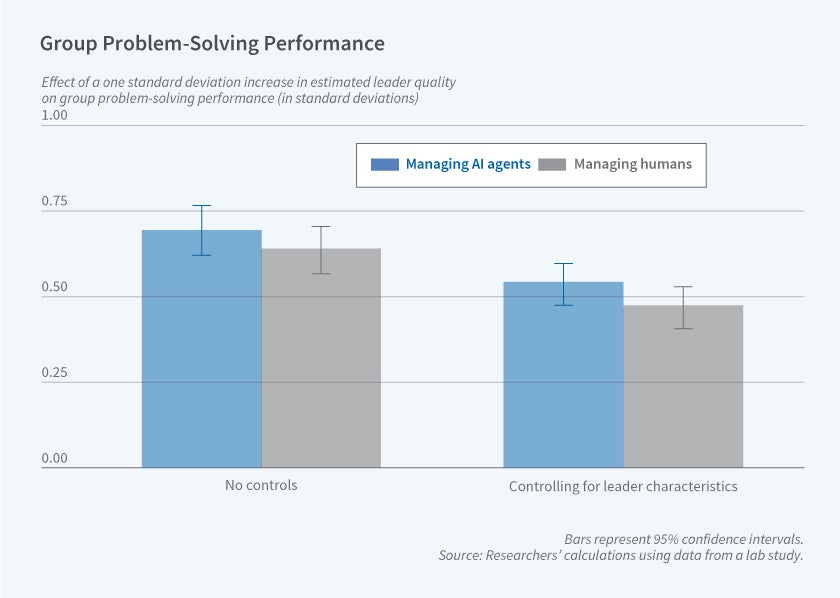
There was a strong positive correlation (𝑝 = 0.81) between leaders’ performance with AI and human teams. This correlation remained strong (𝑝 = 0.69) even after controlling for “hard skills” like task-specific abilities and fluid intelligence, suggesting the AI assessment effectively captured leadership-specific “soft skills.”
In both the AI and human leadership assessments, leader quality explained more than half of the variation in team performance. Replacing an average leader with one who is 1 standard deviation above average in leadership quality increased team performance by approximately 0.65 standard deviations.
Successful leaders, when working with either AI agents or humans, asked more questions, engaged in more conversational turn-taking, and used more plural pronouns (referring to “we” and “us”) than their less-successful peers. Demographic factors like gender, ethnicity, and education did not predict leadership performance in either setting.
The AI-based assessment was significantly more efficient, costing $23 per participant compared to $114 for the human version, while also eliminating the need to coordinate multiple participants simultaneously. This cost reduction could make leadership assessment more accessible and enable more rigorous evaluation of leadership development programs.
The researchers gratefully acknowledge the financial support of the Walmart Foundation.


