Corporate Reporting in the Era of Artificial Intelligence
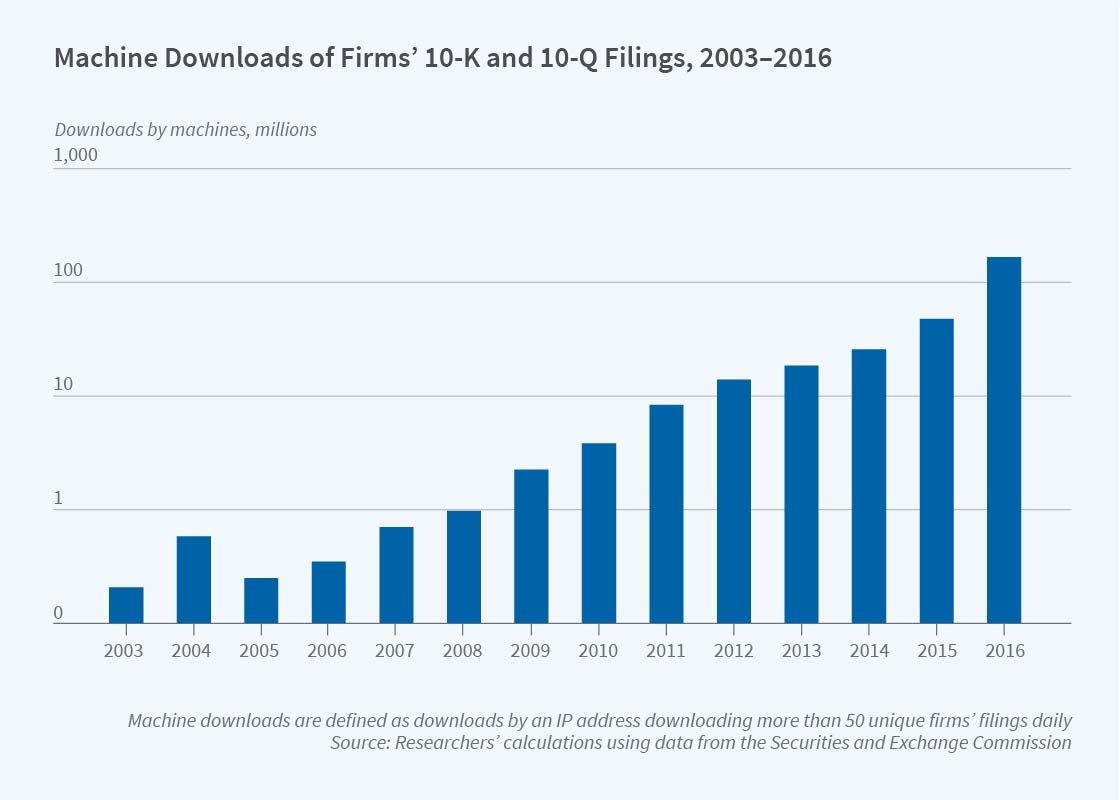
Mechanical downloads of corporate 10-K and 10-Q filings increased from 360,861 in 2003 to around 165 million in 2016.
Companies have long seen annual reports and other corporate disclosures as opportunities to portray their business health in a positive light. Increasingly, the audience for these disclosures is not just humans, but also machine readers that process the information as an input to investment recommendations.
In How to Talk When a Machine Is Listening: Corporate Disclosure in the Age of AI (NBER Working Paper 27950), Sean Cao, Wei Jiang, Baozhong Yang and Alan L. Zhang explore some of the implications of this trend. Rather than focusing on how investors and researchers apply machine learning to extract information, this study examines how companies adjust their language and reporting in order to achieve maximum impact with algorithms that are processing corporate disclosures.
To gauge the extent of a company’s expected machine readership, the researchers use a proxy: the number of machine downloads of the company’s filings from the US Securities and Exchange Commission’s electronic retrieval system. Mechanical downloads of corporate 10-K and 10-Q filings have increased exponentially, from 360,861 in 2003 to around 165 million in 2016. Machine downloads have become the dominant mode during this time — increasing from 39 percent of all downloads in 2003 to 78 percent in 2016.
The researchers find that companies expecting higher levels of machine readership prepare their disclosures in ways that are more readable by this audience. “Machine readability” is measured in terms of how easily the information can be processed and parsed, with a one standard deviation increase in expected machine downloads corresponding to a 0.24 standard deviation increase in machine readability. For example, a table in a disclosure document might receive a low readability score because its formatting makes it difficult for a machine to recognize it as a table. A table in a disclosure document would receive a high readability score if it made effective use of tagging so that a machine could easily identify and analyze the content.
Companies also go beyond machine readability and manage the sentiment and tone of their disclosures to induce algorithmic readers to draw favorable conclusions about the content. For example, companies avoid words that are listed as negative in the directions given to algorithms.
The researchers show this by contrasting the occurrence of positive and negative words from the Harvard Psychosocial Dictionary — which has long been used by human readers — with those from an alternative, finance-specific dictionary that was published in 2011 and is now used extensively to train machine readers. After 2011, companies expecting high machine readership significantly reduced their use of words labelled as negatives in the finance-specific dictionary, relative to words that might be close synonyms in the Harvard dictionary but were not included in the finance publication. A one standard deviation increase in the share of machine downloads for a company is associated with a 0.1 percentage point drop in negative-sentiment words based on the finance-specific dictionary, as a percentage of total word count.
Companies also appear to adjust their use of words associated with potential stock market reactions, such as those that the alternative dictionary labels as litigation-related, uncertain, or demonstrating too little or too much confidence. In contrast, no relationship emerges between high machine readership and the sentiment of words as specified by the Harvard dictionary.
Both results demonstrate that company managers specifically consider machine readers, as well as humans, when preparing disclosures.
Machines have become an important part of the audience not just for written documents but also for earnings calls and other conversations with investors. Managers who know that their disclosure documents are being parsed by machines may also recognize that voice analyzers may be used to identify vocal patterns and emotions in their commentary. Using machine learning software trained on a sample of conference call audio from 2010 to 2016, the researchers show that the vocal tones of managers at companies with higher expected machine readership are measurably more positive and excited.
— Dylan Parry


