Machine Learning in Health Care
The use of machine learning (ML) in economics is on the rise, including in the analysis of health care questions. In June, the NBER hosted a conference on Machine Learning in Health Care, organized by David Cutler, Sendhil Mullainathan, and Ziad Obermeyer.
Susan Athey led off the meeting with a discussion of The Impact of Machine Learning in Economics. She offered a "relatively narrow" definition of ML as "a field that develops algorithms designed to be applied to datasets, with the main areas of focus being prediction (regression), classification, and clustering or grouping tasks." She notes that a strength of ML is its ability to estimate and compare many models, which is particularly useful when there are many covariates or when the researcher wishes to estimate the model flexibly. ML works well when the problem is simple, such as a prediction or classification task, where the model can be estimated using one part of the data and tested on another. However, many questions in economics involve causal inference, where there is no unbiased estimate of the truth available for comparison; Athey suggested that more work will be needed to apply an algorithmic approach in such cases. She predicted "the combination of ML and newly available datasets will change economics in fairly fundamental ways, ranging from new questions, to new approaches to collaboration (larger teams and interdisciplinary interaction), to a change in how involved economists are in the engineering and implementation of policies."
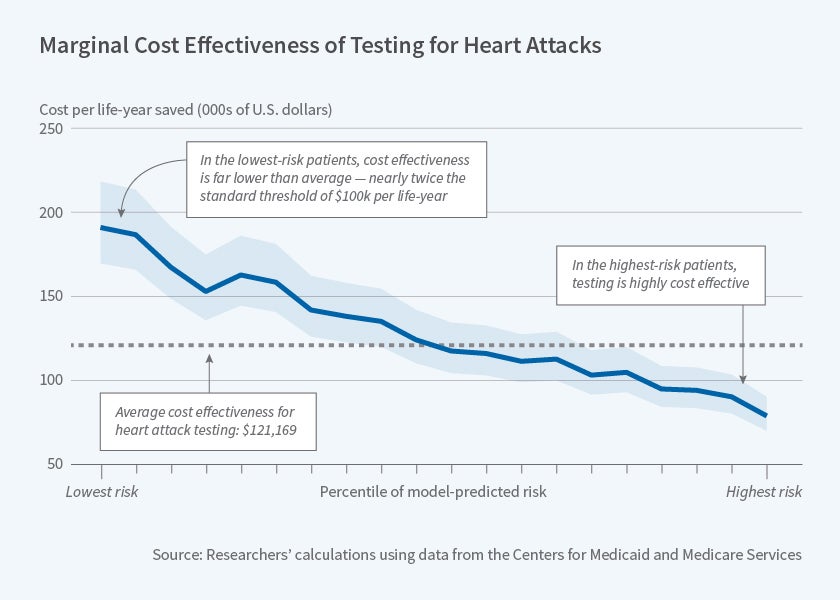
Ziad Obermeyer and Sendhil Mullainathan explore the potential of ML to identify low-value health care in their new study, Are We Over-Testing? Using Machine Learning to Understand Doctors' Decisions. The researchers apply ML tools to study testing for heart attack in the emergency setting. Intensive tests such as stress testing or catheterization allow doctors to detect an acute or impending blockage, enabling patients to receive life-saving treatments such as a stent or open-heart surgery. However, these tests cost thousands of dollars and the average yield of the test (share of tested patients with a serious blockage) is often as low as 1 to 2 percent.
The researchers use national Medicare claims, as well as detailed electronic health record data from a large hospital, to compare doctors' testing decisions to individualized, prospective risk estimates obtained via ML. They find a substantial number of patients with very low model-predicted risk ex ante, whom doctors nevertheless decide to test. Tests for these patients have very low yield and would not be considered cost-effective at the standard threshold of $100,000 per life-year saved. Testing is cost-effective for patients in the top quartile of model-predicted risk, yet there are untested patients within this population. Many of these patients go on to develop serious complications, or to die, in the weeks after their emergency visits.
There is substantial variation across doctors in their propensity to test, and doctors who test more than average tend to test more high-risk patients as well as more low-risk patients. This suggests that rather than encouraging high-testing doctors to behave like low-testing doctors, there may be greater gains from using algorithmic decision-making to identify high-risk patients — the researchers estimate that by so doing, doctors could find 55 percent more heart attacks while testing at the rate of low-testing doctors. They conclude, "these results suggest that both under-testing and over-testing are prevalent, and that targeting misprediction is an important but understudied policy priority."
The other papers presented at the conference also showcased the potential of ML for providing key insights on health care questions. In Triage Judgments in the Emergency Department, David C. Chan Jr. and Jonathan Gruber examine triage nurses' assignment of an emergency severity index (ESI) to emergency department patients. They find that nurses' triage decisions can affect mortality among those patients at risk of dying.
Justine Hastings, Mark Howison, Sarah Inman, and Miraj Shah examine predictors of opioid use among Medicaid patients in Rhode Island in Using Big Data and Data Science to Generate Solutions to the Opioid Crisis. They find that about 4 percent of patients has an adverse event within 5 years, with prison time a particularly strong predictor.
In Managing Intelligence: Skilled Experts and AI in Markets for Complex Products, Jonathan Gruber, Benjamin Handel, Jonathan Kolstad, and Samuel Kina examine the role of agents in Medicare Part D enrollment decisions. They find that more skilled agents have lower expected consumer costs, but that both agents and consumers overweight premiums when choosing a plan. The introduction of a predictive plan recommendation algorithm reduces expected consumer costs, particularly for clients working with low-skilled agents.
Finally, in Use of Care and Cost Exposure: A Story in Heterogeneity, Rahul Ladhania, Amelia Haviland, Neeraj Sood, and Ateev Mehrotra illustrate the methodological opportunities and challenges of using large observational data and statistical machine learning methods to generate hypotheses about subgroups with heterogeneous effects. In one case study with exogenous treatment, the authors find that some of the generated hypotheses hold up and many do not.
The organizers of this conference gratefully acknowledge financial support by the National Institute on Aging of the National Institutes of Health under Award Number P30AG012810. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. Athey gratefully acknowledges financial support from the Toulouse Network for Information Technology, the Cyber Initiative at Stanford University, the Sloan Foundation, and Office of Naval Research grant 17-1-2131. Obermeyer and Mullainathan gratefully acknowledge support from the National Institutes of Health (Office of the Director, grant DP5 OD012161.


