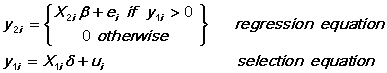
SAMPSEL estimates a generalized Tobit or sample selection model where both the regression and the latent variable which predicts selection are linear regression functions of the exogenous variables. Either a censored (regression variables not observed for non-selected observations) or truncated (all variables not observed) model may be estimated.
SAMPSEL (MILLS=<series>, nonlinear options)
<probit dep var> <probit indep vars> | <regression dep var> <regression indep vars> ;
Usage
The model estimated by SAMPSEL is the Tobit type II model described by Amemiya or the censored regression model with a stochastic threshold described by Maddala (see the references). It can be written as
e(i) and u(i) are assumed to be joint normally distributed:
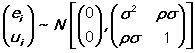
In the output, the variance of the regression equation is denoted SIGMA and the correlation coefficient is denoted RHO. The variance of the selection (probit) equation is normalized to one without loss of generality.
To use the procedure to estimate this model, supply the name of a zero/one variable which tells whether the observation was observed or not (y(1)>0) as the probit dependent variable, the regressors X1 as the probit independent variables, y(2) as the regression dependent variable, and X2 as the regression independent variables. Missing values for the regression variables are allowed for those observations for which y(1) = 0.
If y(1) is always greater than zero, the truncated (conditional) model is estimated (Bloom and Killingsworth 1985). This is flagged with the message "Latent Selection Variable". HCOV=B are the only standard errors available for the truncated case. The identifying condition that there be variables other than the constant in the probit equation is not checked.
Output
The output of SAMPSEL begins with an equation title and the name of the dependent variable. Starting values and diagnostic output from the iterations will be printed. Final convergence status is printed. This is followed by the mean of the dependent variable, number of positive observations, sum of squared residuals, R-squared, and a table of right hand side variable names, estimated coefficients, standard errors and associated t-statistics.
SAMPSEL also stores some of these results in data storage for later use. The table below lists the results available after a SAMPSEL command.
|
name |
type |
length |
description |
|
@LHV |
list |
1 |
Name of dependent variable |
|
@RNMS |
list |
#vars |
list of names of right hand side variables |
|
@YMEAN |
scalar |
1 |
Mean of the probit dependent variable |
|
@NOB |
scalar |
1 |
Number of observations |
|
@NPOS |
scalar |
1 |
Number of positive observations in probit equation |
|
@SSR |
scalar |
1 |
Sum of squared residuals (regression equation) |
|
@LOGL |
scalar |
1 |
Log of likelihood function |
|
@SBIC |
scalar |
1 |
Schwarz Bayesian Information Criterion |
|
@AIC |
scalar |
1 |
Akaike Information Criterion |
|
@IFCONV |
scalar |
1 |
1 if convergence achieved, 0 otherwise |
|
@NCOEF |
scalar |
1 |
Number of coefficients = number in probit + number in regression + 2 |
|
@NCID |
scalar |
1 |
Number of identified coefficients |
|
@COEF |
vector |
#vars |
Coefficient estimates |
|
@SES |
vector |
#vars |
Standard errors |
|
@T |
vector |
#vars |
T-statistics |
|
@GRAD |
vector |
#vars |
Gradient of log likelihood at convergence |
|
@VCOV |
matrix |
#vars* #vars |
Variance-covariance of estimated coefficients |
|
@DPDX |
matrix |
#vars*2 |
Mean of probability derivatives for selection equation |
|
@RES |
series |
#obs |
Residuals for the observed sample |
|
@MILLS |
series |
#obs |
Inverse Mills ratios |
If the regression includes a PDL variable, the following will also be stored:
|
@SLAG |
scalar |
1 |
Sum of the lag coefficients |
|
@MLAG |
scalar |
1 |
Mean lag coefficient (number of time periods) |
|
@LAGF |
vector |
#lags |
Estimated lag coefficients, after "unscrambling" |
Method
The method used is maximum likelihood, obtained by means of a gradient method that uses the Hessian approximation given by the HITER option. Since this likelihood function is known to have multiple local optima frequently, the method of Nawata (1994, 1995, 1996) is used to find the global optimum. In Nawata's method, a grid search is done on the correlation coefficient RHO to find the set of local optima. Then further iterations are done to refine the optima to full precision and choose the global optimum. The grid points used are -.9999, -.99 , -.95, -.9, -.85, -.8, -.2, -.1, 0, .1, .2, ... .8, .85, .9, .95, .99, .9999.
Sometimes the global optimum shows RHO = 1.0000 or -1.0000 . In these cases, the actual estimate of RHO is slightly less than 1 in absolute value, and the residual covariance matrix is nearly singular. The standard error of RHO and its covariance with other parameters is set to zero in these cases.
MILLS= name of variable where the inverse Mills ratio should be stored. The default is @MILLS.
Standard nonlinear options -- see NONLINEAR.
HITER=N, HCOV=N is the default, except when the truncated model is estimated, in which case HCOV=B is used.
SAMPSEL (PRINT, MAXIT=50, HCOV=NBW) IY C Z | Y C X ;
Amemiya, Takeshi, Advanced Econometrics, Harvard University Press, Cambridge, Massachusetts, 1985, Chapter 13.
Bloom, David E., and Killingsworth, Mark R., "Correcting for Truncation Bias caused by a Latent Truncation Variable," Journal of Econometrics, 1985, pp. 131-135.
Griliches, Z., B. H. Hall, and J. A. Hausman, "Missing Data and Self- selection in Large Panels," Annales de l'Insee, Avril-Sept 1978, pp. 137- 176.
Heckman, James J., Sample Selection Bias as a Specification Error, Econometrica 47(1974), pp. 153 162.
Maddala, G. S., Limited-Dependent and Qualitative Variables in Econometrics, Cambridge University Press, Cambridge, 1983, Chapter 6.
Nawata, Kazumitsu,"Estimation of Sample Selection Bias Models by the Maximum Likelihood Estimator and Heckman's two-step Estimator," Economics Letters 45, 1994, pp. 33-40.
Nawata, Kazumitsu,"Estimation of Sample Selection Models by the Maximum Likelihood Method," Mathematics and Computers in Simulation 39, 1995, pp. 299-303.
Nawata, Kazumitsu, and Nobuko Nagase, "Estimation of Sample Selection Bias Models," Econometric Reviews 15, 1996, pp. 387-400.
Olsen, R. J., "Distributional Tests for Selectivity Bias and a More Robust Likelihood Estimator," International Economic Review 23, 1982, pp. 223-240.