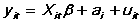
PANEL obtains estimates of linear regression models for panel data (several observations or time periods for each individual). Total, between groups, within groups, and variance components may be obtained. In addition one and two-way random effects models may be estimated by maximum likelihood. The data may be unbalanced (different number of observations per individual. PANEL can also compute means by group and perform F tests between groups.
PANEL (ALL, BETWEEN, BYID, ID=<id series>, MEAN, PRINT, REG, REI, REIT, ROBUST,SILENT,
T=<number of time periods>, TERSE, TIME=<time series>, TOTAL, VARCOMP,
VBET=<between variance>, VSMALL, VWITH=<within variance>, WITHIN, Nonlinear options)
<dependent variable> <list of independent variables> ;
Usage
The basic PANEL statement is like the OLSQ statement: first list the dependent variable and then the independent variables. C is optional; an intercept term is central to these models and will be added if it is not present. You may have as many independent variables as you like subject to the overall limits on the number of arguments per statement and the amount of working space, as well as the number of data observations you have available. The observations over which the models are computed are determined by the current sample. PANEL treats missing values, lags, and leads correctly. That is, lags and leads are applied only within an individual.
Your data must be set up with all the time periods for each individual together. Additionally, you must specify when the observations for one individual end and data for the next individual begins. The default method is to provide a series named @ID which takes on different values for each individual. If your data are balanced (the same number of time periods for every individual), the T= option can be used. If the data are not in this order, the SORT command can be used to reorder them; you could also sort the data by year and then individual if you wish to do variance components in the time dimension. Usually it is best to use the FREQ (PANEL) command at the top of your run to specify such ID variables, internal frequency and starting date, etc. Then these options will be used for all PANEL, AR1, GENR, etc. commands within the run.
The models you wish to estimate are specified in the options list. The default is to estimate the total, between, within, and variance components models. For the VARCOMP (random effects) model, there are additional options that specify how to compute the variance components. Small- or large sample formulas may be used, or the user can supply the values directly. If negative variances are computed using the small sample method, the method switches over to the large sample formulas, which always result in positive values. PANEL also computes a Hausman test for correlated effects by comparing the WITHIN (fixed effects) and VARCOMP (random effects) estimators.
The REI and REIT options are used to obtain maximum likelihood estimates of the one and two-way random effects models.
Output
The output begins with a title and a summary of the panel structure: number of individuals (NI), number of time periods (T), and total number of observations (NOB). If the data are unbalanced, TMIN and TMAX will be printed. For each estimator, a table of regression coefficients and their standard errors is printed, along with name of the dependent variable, the sum of squared residuals, standard error of the regression, mean and standard deviation of the dependent variable, R-squared, and adjusted R-squared.
Other output varies by estimator. For the two-way model, the Ahrens-Pincus measure of the degree of unbalancedness is also printed; this measure is one for balanced data; values less than one provide an indication of how far the data is from balanced. See the method section for the definition of this statistic and the reference for details on its interpretation.
MEAN prints a table of means for each individual. @MEAN (#obs*#vars) is stored, and excludes any constant term.
BYID prints an F test vs. TOTAL (labelled F-stat for A,B=Ai,Bi), and an F test vs. WITHIN (labelled F-stat for Ai,B=Ai,Bi), in the output of the respective estimators. Only @COEFI (the individual coefficient estimates) and @SSRI (the individual sum or squared residuals) are stored. Use the PRINT option to print @COEFI.
WITHIN prints an F test vs. TOTAL (labelled F-stat for A,B=Ai,B), and stores @FIXED effects vector.
VARCOMP prints the actual variance components, the method used to compute them, and the implied differencing factor (THETA). A Hausman specification test comparing VARCOMP (null hypothesis) and WITHIN is computed.
PANEL stores the standard regression results in data storage for later use using @names, but with B, T, V, W, REI, and REIT appended to distinguish between the different estimators. For example, @COEFW is the within coefficients, @RESW are the within residuals, and @SSRV is the sum of squared residuals from VARCOMP. @RESB is a matrix.
In the table below, #vars is equal to the number of right hand side variables plus one (for the constant) for the T, B, W, and V estimators. For the REI estimator, #vars includes the estimate of RHO_I (the within group correlation) and SIGMA2 (the total standard error). For the REIT estimator, #vars includes the estimate of RHO_I, the estimate of RHO_T, the within time correlation, and SIGMA2 (the total standard error).
|
variable |
type |
length |
description |
|
@LHV |
list |
1 |
Name of the dependent variable |
|
@SSRT/I/B/W/V/REI/REIT |
scalar |
1 |
Sum of squared residuals (@SSRI=BYID, etc.) |
|
@S2T/B/W/V/REI/REIT |
scalar |
1 |
Variance of residuals (@S2B=BETWEEN, etc.) |
|
@ST/B/W/V/REI/REIT |
scalar |
1 |
Standard error of the regression |
|
@YMEANT/B/W/V/REI/REIT |
scalar |
1 |
Mean of the dependent variable |
|
@SDEVT/B/W/V/REI/REIT |
scalar |
1 |
Standard deviation of the dependent variable |
|
@NOB |
scalar |
1 |
Number of observations |
|
@RSQT/B/W/V/REI/REIT |
scalar |
1 |
R-squared |
|
@ARSQT/B/W/V/REI/REIT |
scalar |
1 |
Adjusted R-squared |
|
@NCOEFT/B/W/V/REI/REIT |
scalar |
1 |
Number of coefficients |
|
@NCIDT/B/W/V/REI/REIT |
scalar |
1 |
Number of identified coefficients (number with non-zero standard errors ) |
|
@LMHETT/W/V/REI/REIT |
scalar |
1 |
LM heteroskedasticity test |
|
%LMHETT/W/V/REI/REIT |
scalar |
1 |
P-value of LM heteroskedasticity test |
|
@DWT/W/V/REI/REIT |
scalar |
1 |
Durbin-Watson autocorrelation test |
|
%DWUT/W/V/REI/REIT |
scalar |
1 |
Upper bound on P-value of DW |
|
%DWLT/W/V/REI/REIT |
scalar |
1 |
Lower bound on P-value of DW |
|
@LOGLT/W/REI/REIT |
scalar |
1 |
value of the log likelihood |
|
@SBICT/W/REI/REIT |
scalar |
1 |
Schwarz-Bayes information criterion |
|
@AICT/W/REI/REIT |
scalar |
1 |
Akaike information criterion |
|
@HAUS |
scalar |
1 |
Hausman test value |
|
%HAUS |
scalar |
1 |
Hausman test p-value |
|
@HAUSDF |
scalar |
1 |
Hausman test degrees of freedom |
|
@RNMST/B/W/V/REI/REIT |
list |
#vars |
List of names of right hand side variables |
|
@COEFT/I/B/W/V/REI/REIT |
vector |
#vars |
Coefficient estimates |
|
@SEST/B/W/V/REI/REIT |
vector |
#vars |
Standard errors |
|
@TT/B/W/V/REI/REIT |
vector |
#vars |
T-statistics |
|
@FIXED |
vector |
#individuals |
Fixed effect estimates |
|
@VCOVT/B/W/V/REI/REIT |
matrix |
#vars*#vars |
Variance-covariance of estimated coefficients |
|
@REST/I/B/W/V/REI/REIT |
series |
#obs |
Residuals = actual - fitted values of the dependent variable. |
Method
The model estimated is
PANEL computes means for each variable by individual. These are used directly in the BETWEEN regression. WITHIN subtracts the individual means from each variable and runs a regression on this transformed data (any variables which are constant over time for every individual are not identified).
VARCOMP does a transformation similar to WITHIN. (1-SQRT(theta)) times the mean is subtracted from each variable (including the constant term), where theta is given by
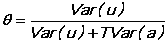
T does not have to be the same for each individual. The small and large sample formulas used for the variance components are:
|
variance |
small sample |
large sample |
|
within |
@SSRW/(NOB-NX-NI) |
@SSRW/NOB |
|
total |
@SSRT/(NOB-NX-1) |
(not used) |
|
between |
VTOT-VWITH |
(@SSRT-@SSRW)/NOB |
If the small sample formula produces a non-positive variance, PANEL switches over to the large sample formulas automatically. The large sample formulas are asymptotically correct if T is (becomes) large relative to N(i) (not usually the case); otherwise they will be biased. Note that if theta=1, this corresponds to a zero between variance and VARCOMP will produce the same estimates as TOTAL. If theta=0, this corresponds to a zero within variance, and VARCOMP will be the same as WITHIN.
For each F test (described under Output), a P-value and an alternative critical value are printed. The critical value has a size which becomes smaller as the number of observations grows -- this is an alternative to the conventional testing procedure, which is certain to reject all point null hypotheses when sample sizes become large. It is based on a Bayesian flat prior, and computed from the formula in the Leamer reference:
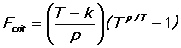
Where T = total number of observations, k = number of estimated parameters in the unrestricted model, and p = the number of restrictions.
All regressions are computed with the standard orthonormalized data matrices to insure accurate coefficients and variance estimates under possible multicollinearity (methods using moment matrices are less accurate).
The Durbin-Watson test and bounds on its P-values are computed following the Bhargava et al reference, extended to the unbalanced data case. The P-values are computed using the Farebrother-Imhof method, since there can be multiple equal eigenvalues.
The REI estimates are obtained with a grid search over rho in order to avoid the problem of multiple local optima. Estimates are then refined to choose the global optimum and multiple optima are reported. RHO is bounded between -1/(Max(T)-1) and 1, where Max(T) is the maximum number of observations per individual. See Maddala and Nerlove (1971). The REIT estimates are obtained using the method of Davis (2002). The Ahrens-Pincus measure of unbalancedness is defined as follows:
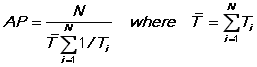
This can be interpreted as the inverse of the product of the geometric and arithmetic means of the T(i) over the sample of individuals. Note that AP is always less than or equal to 1 and that it equals one only when T(i)=T for all i.
ALL/NOALL turns all regressions on or off (equivalent to the combination of TOTAL, BETWEEN, WITHIN, VARCOMP).
BETWEEN/NOBETWEEN selects the "between" estimator -- a regression on the means for each individual.
BYID/NOBYID does a separate regression for each individual, and computes F tests for equality with the TOTAL and WITHIN estimators.
ID= the name of a series which takes on a different value for each individual. The default is @ID; alternatives are the T= and TIME= options.
MEAN/NOMEAN causes the means for each individual to be printed in a table. This can be used in conjunction with the NOREG option to print means only (to suppress all the default regression models). These individual means are stored in the NI x (1+NX) matrix @MEAN, where the first column is the dependent variable.
PRINT/NOPRINT prints @COEFI in conjunction with BYID, and prints @FIXED for within.
REG/NOREG is used with the MEAN option above. To suppress some regression models, but print others, use the individual options -- NOBETW to suppress the BETWEEN output, etc.
REI/NOREI specifies that ML estimates of the one-way random effects model are to be obtained.
REIT/NOREIT specifies that ML estimates of the two-way random effects model are to be obtained.
ROBUST/NOROBUST calculates heteroskedasticity-robust standard errors (HCTYPE=1; see OLSQ) for the WITHIN coefficients. If this option is used, the Hausman test comparing WITHIN and VARCOMP is not computed.
SILENT/NOSILENT can be used to turn off all the regression output.
T= the number of time periods for each individual (for balanced data only). For unbalanced data, use the ID= option.
TERSE/NOTERSE can be used to turn off most of the regression output, except the coefficients and standard errors.
TIME= the name of a time period series which increases in value for each individual and decreases between individuals. Alternatives are the ID= and T= options. Example: TIME=YEAR. This is not considered sufficient for identifying individuals, since the last time period for one individual may be less than the first time period of the next individual.
TOTAL/NOTOTAL selects the "total" or "pooled" estimator -- a plain OLS regression on the whole sample.
VARCOMP/NOVARCOMP selects the "variance components" or "random effects" estimator. The method of selecting the variance components is controlled with the VBET, VSMALL, and VWITH options described below. Unbalanced data are not a problem. Variance components in the time dimension are not available.
VBET= specifies the value of the "between" variance for VARCOMP.
VSMALL/NOVSMALL selects the small sample variance components formulas for VARCOMP (as opposed to the large sample formulas). Small sample formulas are unbiased but can result in negative variances, while large sample formulas are biased but always yield positive variances. To supply your own variance values, use VBET= and VWITH=.
VWITH= specifies the value of the "within" variance for VARCOMP.
WITHIN/NOWITHIN selects the "within" or "fixed effects" estimator (different intercepts for each individual.
Nonlinear options may be used for the REI and REIT estimators. See NONLINEAR.
Global FREQ (PANEL) command, with ID variable to identify individuals:
FREQ(PANEL,ID=FIRM); DY=Y-Y(-1);
PANEL DY C X X(-1);
Estimate all models (7 years per individual, balanced data), and print individual means:
PANEL(T=7,MEAN,BYID) LRNDL5 C PATENTS LRNDL4;
Print VARCOMP output only, using @ID or FREQ(PANEL) to distinguish individuals:
PANEL(NOTOT,NOBET,NOWITH) LRNDL5 C PATENTS LRNDL4;
Estimate all models except BYID, use large sample formulas for VARCOMP:
PANEL(NOVSMALL) LRNDL5 C PATENTS LRNDL4;
Print individual means only:
PANEL(MEAN,NOREG) LRNDL5 C PATENTS LRNDL4;
Ahn, S.C., and P. Schmidt, Efficient Estimation of Panel Data Models with Exogenous and Lagged Dependent Regressors, Journal of Econometrics 68 (1995) 5-27.
Ahrens, H., and R. Pincus, "On two measures of unbalancedness in a one-way model and their relation to efficiency, Biometric Journal 23 (1981), pp. 227-235.
Baltagi, Badi, Econometric Analysis of Panel Data, Wiley & Sons, New York, 1995 (first edition).
Bhargava, A., L. Franzini, and W. Narendanathan, Serial Correlation and the Fixed Effects Model, Review of Economic Studies XLIX (1982), pp.533-549.
Chamberlain, Gary, Multivariate Regression Models for Panel Data, Journal of Econometrics 18(1982), pp. 5 46.
Chamberlain, Gary, Panel Data, in Griliches and Intriligator (eds.), Handbook of Econometrics, Volume II, North Holland Publishing Co., Amsterdam, 1985.
Davis, Peter, "Estimating Multi-Way Error Components Models with Unbalanced Data Structures," Journal of Econometrics 106 (July 2002), pp. 67-95.
Farebrother, R. W., "Algorithm AS 256", Applied Statistics 39, 1990. Pascal code posted on StatLib.
Hsiao, Cheng, Analysis of Panel Data, Cambridge University Press, Cambridge, England, 1986.
Leamer, Edward E., Specification Searches: Ad Hoc Inference with Nonexperimental Data, Wiley, New York, 1978, p. 114.
Maddala, G. S., Econometrics, McGraw-Hill, New York, 1977, pp. 326-329.
Maddala, G. S., and M. Nerlove. Econometrica (1971).
Nerlove, Marc, Likelihood Inference in Econometrics, Academic Press, New York, 2000.
StatLib, http://lib.stat.cmu.edu/apstat/